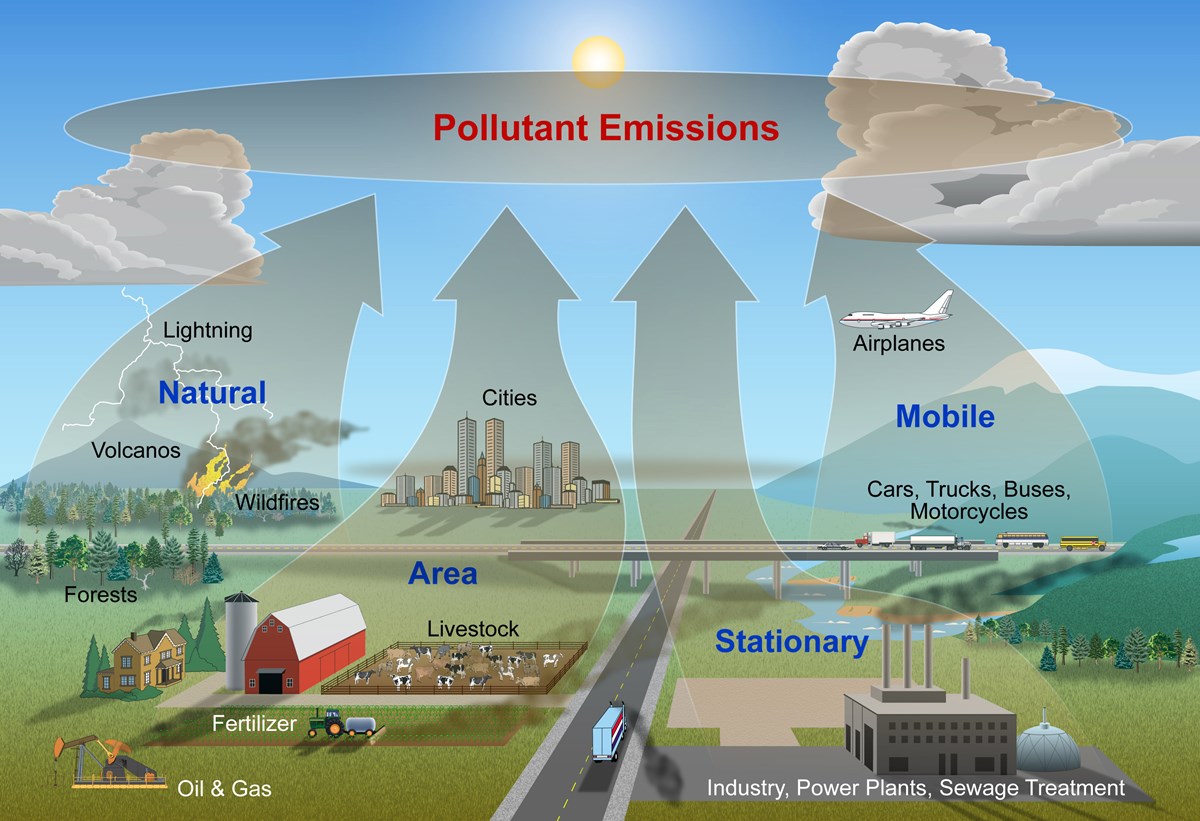
Basic Information
The MCNC Environmental Modeling Center (EMC) created the Sparse Matrix Operator Kernel Emissions (SMOKE) Modeling System to allow emissions data processing methods to integrate high-performance-computing (HPC) sparse-matrix algorithms. The SMOKE system is a significant addition to the available resources for decision-making about emissions controls for both urban and regional applications. It provides a mechanism for preparing specialized inputs for air quality modeling research, and it makes air quality forecasting possible. The SMOKE system continues to develop and improve at the University of North Carolina at Chapel Hill’s Institute for the Environment (IE).
SMOKE can process criteria gaseous pollutants such as carbon monoxide (CO), nitrogen oxides (NOx), volatile organic compounds (VOC), ammonia (NH3), sulfur dioxide (SO2); particulate matter (PM) pollutants such as PM 2.5 microns or less (PM2.5) and PM less than 10 microns (PM10); as well as a large array of toxic pollutants, such as mercury, cadmium, benzene, and formaldehyde. In fact, SMOKE has no limitation regarding the number or types of pollutants it can process.
The purpose of SMOKE (or any emissions processor) is to convert the resolution of the emission inventory data to the resolution needed by an air quality model. Emission inventories are typically available with an annual-total emissions value for each emissions source, or perhaps with an average-day emissions value. The AQMs, however, typically require emissions data on an hourly basis, for each model grid cell (and perhaps model layer), and for each model species. Consequently, emissions processing involves transforming an emission inventory through temporal allocation, chemical speciation, and spatial allocation, to achieve the input requirements of the AQM.
The purpose of SMOKE is to convert the resolution of the data in an emission inventory to the resolution needed by an air quality model. Emission inventories typically have an annual-total emissions value for each emissions source, or perhaps an average-day emissions value. The AQMs, however, typically require emissions data on an hourly basis, for each model grid cell (and perhaps model layer), and for each model species. Consequently, to achieve the input requirements of the AQM, emissions processing must (at a minimum) transform inventory data by temporal allocation, chemical speciation, spatial allocation, and perhaps layer assignment.
Inventory data types
SMOKE processes criteria, particulate, toxics, and activity data inventories. Activity data will be discussed along with on-road mobile sources in the next section. By criteria inventories, we mean inventories containing EPA’s criteria pollutants: carbon monoxide (CO), nitrogen oxides (NOx), and volatile organic compounds (VOC) or total organic gases (TOG). Particulate inventories contain ammonia (NH3), sulfur dioxide (SO2), particulate matter (PM) of size 10 microns or less (PM10), and PM of size 2.5 microns or less (PM2.5).
Additionally, SMOKE can process inventories with pre-speciated criteria and/or particulate emissions. For example, elemental carbon of size 2.5 microns or less can be provided as input to SMOKE directly, instead of letting SMOKE’s speciation step compute it from the PM2.5 total emissions. To ensure that SMOKE correctly processes the data when you are using pre-speciated emissions, other input files must be configured in specific ways.
In addition to changing the resolution of the data, SMOKE must also provide the AQM input files in the correct file format. SMOKE can create the Input/Output Applications Programming Interface (I/O API) Network Common Data Form (NetCDF) output format needed by the CMAQ model. It can also create the Fortran binary format for the 2-D emissions needed by UAM, and CAMX, and the ASCII elevated-point-source format used by the Ptsrce preprocessor to these models. File format is also important for the input files used by SMOKE, most of which are ASCII files, but some of which are I/O API NetCDF or CF-compliant NetCDF format files.
The toxics inventories that SMOKE can process are data from the National Emission Inventory (NEI) for Hazardous Air Pollutants (HAPs). This inventory contains hundreds of specific compounds representing the 188 HAPs defined by the Clear Air Act. The original list of 189 HAPs and modifications representing the current list are available from the EPA’s web site. The reason the inventory contains many more pollutants than 188 is because several on the list of 188 are pollutant groups, such as polycyclic organic matter, cyanide compounds and numerous metal compounds including chromium compounds, cadmium compounds, manganese compounds, and others. Note that because of these groups, specific compounds in the inventory in one inventory year may not exactly match the compounds in another inventory year. For example, one may have lead oxide reported one year but not in a subsequent year. However, those compounds not belonging to compound groups are likely to be in the inventory year after year, particularly the common gaseous HAPs emitted by mobile sources such as benzene, 1,3-butadiene, acrolein, formaldehyde, and acetaldehyde.

Inventory source categories and SMOKE processing capabilities and categories