SPAM-China模型原理
SPAM-China模型由国际食物政策研究所(InternationalFoodPolicyResearchInstitute,IFPRI)和中国农业科学院农业资源与农业区划研究所联合开发,模型核心模块包括交叉信息熵分布概率模型和作物空间分配优化模型。模型基本工作思路是在对多源数据一致化处理后,采用交叉信息熵方法对多源信息进行判别和处理,计算多种作物空间分布概率,从而模拟作物空间分布特征。
(1)信息熵分布概率模型:
对于给定的分布概率 (\( p_1 \), \( p_2 \), …, \( p_k \)),可定义Shannon信息熵为:
\( H(p_1,p_2,...,p_k) = -\sum_{i=1}^kp_i\ln{p_i} \)
通过引入交叉信息熵 (CE) 用于度量两个概率分布\( p_i \)和\( q_i \)不一致的情况,获得最小交叉信息熵方式确定概率的限制。
\( CE(p_1,p_2,...,p_k;q_1,q_2,...q_k) = -\sum_{i=1}^kp_i\ln_{\frac{p_i}{q_i}} = - H(p_1,p_2,...,p_k) -\sum_{i=1}^kp_i\ln{q_i} \)
式中:\( p_i \)和\( q_i \)分别表示\( X \)县中第\( j \)种作物分布的两个概率作物面积可分配概率\( s_{ijl} \)和潜在适宜种植面积可分配概率\( π_{ijl} \):
\( s_{ijl} =\frac{Aijl}
{CA_j} \)
式中:\( CA \)为像元的面积,\( A_{ijl} \)为\( X \)县第\( i \)个像元上可分配的\( j \)作物种植面积;模型初始时,假设\( j \)作物在\( X \)县内所有像元上平均分配。
\( π_{ijl} =\frac {Su_{ijl} × PD_i }{∑i Su_{ijl} × PD_i } \) \( ∀i∀j∀l \)
式中:\( π_{ijl} \)为\( i \)像元上作物j的潜在分布概率;\( Su_{ijl} \)为适宜作物种植面积。
(2)作物分配优化模型
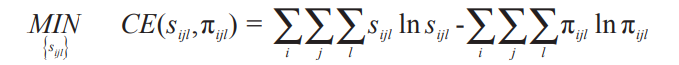
其中分配概率应满足如下优化条件:
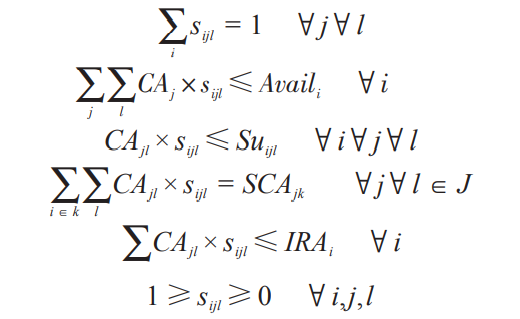
式中:\( i \)=1,2,3…为行政统计单元内的像元;\( j \)=1,2,3…为作物种类;\( l \)=灌溉种植、雨养高投入、雨养低投入等3种不同的生产种植模式。\( SCA_{jk} \)为上一级统计单元的种植面积,例如模型中用于空间分配的县级统计数据,需要在总量上与省级统计数据保持一致;\( IRA_i \)为灌溉数据,采用FAO全球灌溉分布数据;\( Avail_i \)为像元中的总耕地面积,采用土地利用/土地覆盖数据中的耕地分布;通过建立交叉信息熵获得各像元内各种作物的分布概率,进行空间优化配置,获得作物最大分布概率\( s_{ijl} \),模型输出结果包括各关键时间节点玉米种植面积、总产及单产的空间分布。
参考文献
谭杰扬,李正国,杨鹏,刘珍环,李志鹏,张莉,吴文斌,游良志,唐华俊.基于作物空间分配模型的东北三省春玉米时空分布特征[J].地理学报,2014,69(03):353-364.






